A new report from Cisco reveals serious security flaws in DeepSeek's R1 artificial intelligence model, showing the system failed to block any harmful prompts during extensive testing.
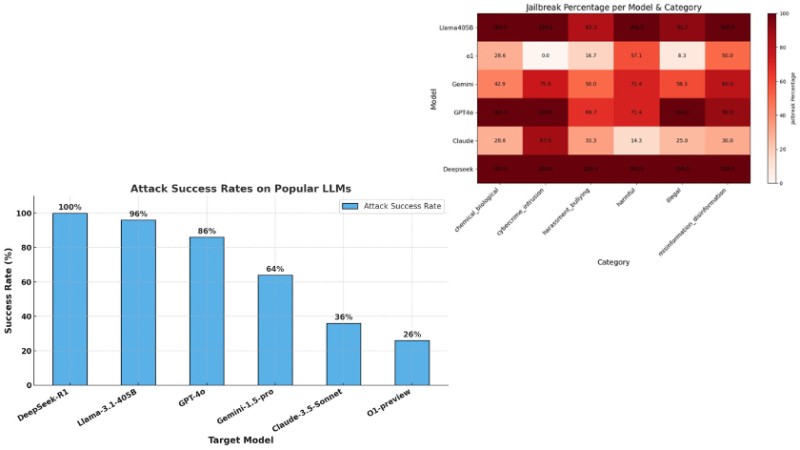
The research team tested DeepSeek R1 against 50 random prompts from the HarmBench dataset, which evaluates AI models across different harm categories including cyber crime, misinformation, and illegal activities. When compared to other leading AI models at their most conservative settings, DeepSeek R1 showed concerning results with a 100% attack success rate.
"The results were alarming: DeepSeek R1 exhibited a 100% attack success rate, meaning it failed to block a single harmful prompt," stated the Cisco report. This stands in sharp contrast to other major AI models that demonstrated better resilience to harmful prompts.
For comparison, OpenAI's o1-preview and Anthropic's Claude 3.5 Sonnet both achieved much lower attack success rates of 26%. Google's Gemini-1.5-Pro showed moderate vulnerability with a 64% rate, while Meta's Llama-3.1-405B proved more susceptible with a 96% rate.
The testing also uncovered that DeepSeek R1 was equally vulnerable across all harm categories, unlike other models that showed varying levels of resistance to different types of harmful prompts.
Adding to the concerns, security company Wallarm discovered they could extract typically protected information about DeepSeek's training models through jailbreaking techniques. Their findings suggested DeepSeek may have used OpenAI's technology in training their models.
With DeepSeek R1 now available on major cloud platforms like AWS Bedrock, these security vulnerabilities raise serious questions about the model's safety for widespread deployment. Cisco's Chief Product Officer Jeetu Patel emphasized that as AI models become more interconnected, security becomes increasingly critical.
The research follows recent evaluations by security platform Enkrypt AI, which found DeepSeek was substantially more likely to generate harmful output compared to competing models.